在本博客中,我们将探索高通在 Snapdragon SoC 上实现的 TrustZone。如果您还没有阅读之前的博客文章,我在其中详细介绍了 TrustZone。
从哪里开始?
首先,由于高通的 TrustZone 实现是闭源的,据我所知,没有公开的文档详细说明其架构或设计,我们可能需要对包含 TrustZone 代码的二进制文件进行逆向工程和分析。
获取TrustZone映像
我们可以尝试从两个不同的位置提取映像;要么从设备本身,要么从设备的工厂映像。
我的个人 Nexus 5 设备已经获取了 root 权限,因此从设备中提取映像应该非常简单。由于映像存储在 eMMC 芯片上,而 eMMC 芯片的块和分区在“/dev/block/platform/msm_sdcc.1”下可用,我可以通过使用“dd”将相关分区复制到我的桌面。
此外,这些分区在“/dev/block/platform/msm_sdcc.1/by-name”下有有意义的命名链接。

这里有两个分区,一个名为“tz”(代表TrustZone),一个名为“tzb”,用作“tz”映像的备份映像,与其完全相同。
但是,通过这种方式提取映像后,仍然不满意,原因有两个:
- 虽然 TrustZone 映像存储在 eMMC 芯片上,但它可能很容易对“普通世界”(通过要求系统总线上的 AxPROT 位被设置)变得不可访问,或其中的几个部分可能会丢失。
- 拉取整个分区的数据并不透露有关映像实际(逻辑)边界的信息,因此需要额外的工作才能确定映像实际上的结束位置。(实际上,“tz”映像是一个 ELF 二进制文件,其大小包含在 ELF 头中,但这只是一种特殊情况)。
因此,提取了一个设备映像后,让我们看看出厂映像。
Nexus 5 的出厂映像都可以从谷歌上下载。出厂映像包含一个 ZIP 文件,其中包含所有默认映像,此外还包含引导加载程序映像。
下载出厂映像并搜索与 TrustZone 相关的字符串后,很快就可以发现引导加载程序映像包含了所需的代码。
但是,在这里仍然有一个小问题要解决 - 引导加载程序映像以一种未知的格式存储(尽管也许可以通过一些 Google 技巧找到需要的答案)。无论如何,使用十六进制编辑器打开该文件并猜测其结构后发现,该格式实际上相当简单:
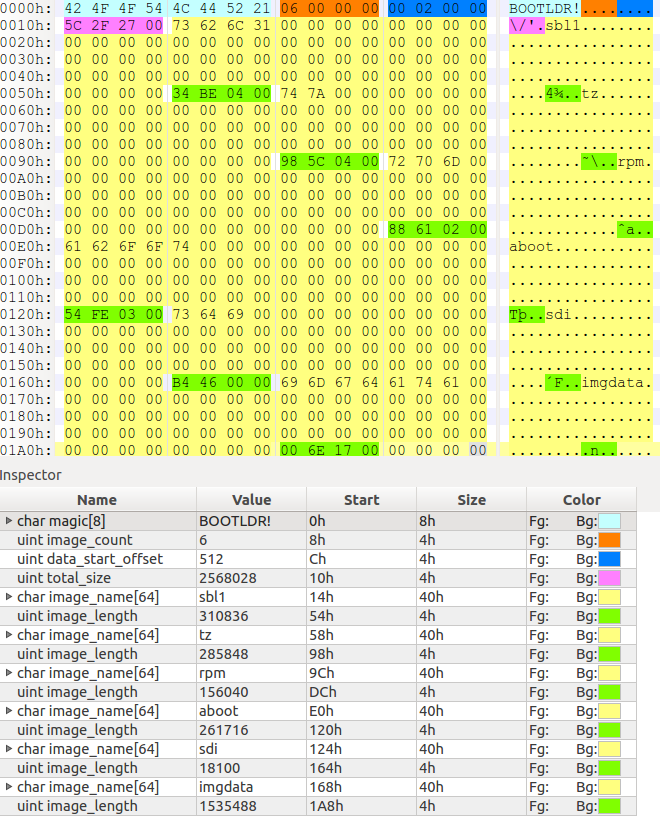
引导加载程序文件的结构如下:
- 魔数(“BOOTLDR!”)- 8个字节。
- 镜像的数量 - 4个字节。
- 镜像数据开头相对于文件开头的偏移量 - 4个字节。
- 包含在镜像中的数据的总大小 - 4个字节。
- 一个数组,其项数与上面的“镜像数量”字段相匹配。数组中的每个条目都有两个字段:镜像名称 - 64个字节(填充为零);镜像长度 - 4个字节。
如您在上面的图片中所看到的,引导加载程序映像包含一个名为“tz”的映像,这是我们要找的映像。为了解包此文件,我编写了一个小型 Python 脚本(在此处提供),该脚本接收引导加载程序映像并解包其中包含的所有文件。
提取映像后,将其与先前从设备中提取的映像进行比较,我验证它们确实是相同的。因此,我想这意味着我们现在可以继续检查 TrustZone 映像了。
修复 TrustZone 映像
首先,检查文件会发现它实际上是一个 ELF 文件,这是非常好的消息!这意味着内存段及其映射的地址应该对我们可用。
在使用 IDA Pro 打开文件并让自动分析运行一段时间后,我想开始反汇编文件。然而,令人惊讶的是,似乎有很多跳转到未映射地址(或者说指向不包含在“tz”二进制文件中的地址)的分支。
仔细观察后,似乎所有指向无效地址的绝对分支都位于文件的第一个代码段中,并且它们指向未映射的高地址。此外,没有绝对分支指向该第一个代码段的地址。
这似乎有些可疑…那么我们来看一下 ELF 文件的结构如何?执行 readelf 命令会显示以下内容:

有一个空段映射到一个更高的地址,实际上与无效绝对分支指向的地址范围相对应!高通的家伙们很聪明。
无论如何,我做出了一个相当安全的猜测,即第一个代码段实际上映射到错误的地址,应该实际上映射到更高的地址-0xFE840000。因此,自然地,我想使用 IDA 的重新定位功能重新定位段,但是惊奇地发现!这会导致 IDA 崩溃:

我其实不确定这是高通有意为之的反调试特性,还是 NULL 段只是他们内部构建过程的结果,但是这可以通过手动修复 ELF 文件来轻松规避。只需要将 NULL 段移动到未使用的地址(因为 IDA 会忽略它),并将第一个代码段从错误的地址(0xFC86000)移动到正确的地址(0xFE840000),如下所示:

现在,在 IDA 中加载镜像后,所有的绝对分支都有效!这意味着我们可以继续分析镜像!
分析 TrustZone 镜像
首先,应该注意的是,TrustZone 镜像是一个相当大的(285.5 KB)二进制文件,有相当少的字符串,而且没有公开的文档。此外,TrustZone 系统是由一个完整的内核组成的,具有执行应用程序等功能,还有更多。所以…不清楚我们应该从哪里开始,因为逆转整个二进制文件可能会花费太多时间。
由于我们想从应用处理器攻击 TrustZone 内核,最大的攻击面可能是安全监控调用,它使 "正常世界 "能够与 "安全世界 "互动。
当然,应该注意的是,还有其他的载体可以让我们与 TrustZone 进行交互,比如共享内存,甚至是中断处理,但是由于这些所构成的攻击面要小得多,所以从分析 SMC 调用开始可能更好。
那么,我们如何找到 TrustZone 内核处理 SMC 调用的地方呢?首先,让我们回顾一下,当执行 SMC 调用时,与处理 SVC 调用(即"正常世界"中的常规系统调用)类似,"安全世界"必须注册向量的地址,当遇到这种指令时,处理器将跳转到该向量。
"安全世界"的等价物是 MVBAR(监控向量基址寄存器),它提供了包含处理器在"安全世界"处理不同事件的处理功能的向量地址。
访问 MVBAR 是通过 MRC/MCR 操作码完成的,其操作数如下:

因此,这意味着我们可以简单地在 TrustZone 镜像中搜索具有以下操作数的 MCR 操作码,我们应该能够找到"监控向量"。事实上,在 IDA 中搜索该操作码会得到以下匹配结果:

正如你所看到的,"start"符号(顺便说一下,它是唯一导出的符号)的地址被加载到 MVBAR 中。根据 ARM 的文档,"监控向量"有以下结构:

这意味着,如果我们看一下前面提到的"start"符号,我们可以给该表中的地址分配以下名称:
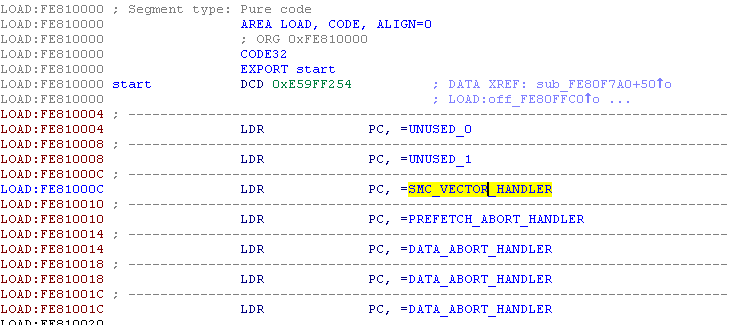
现在,我们可以分析一下 SMC_VECTOR_HANDLER 函数。实际上,这个函数负责相当多的任务;首先,它将所有的状态寄存器和返回地址保存在一个预定义的地址中(在"安全世界"中),然后,它将堆栈切换到一个预先分配的区域(也在"安全世界"中)。最后,在进行了必要的准备工作后,它继续分析用户要求的操作并根据它进行操作。
由于发布 SMC 的代码存在于 Linux 内核的高通公司 MSM 分支中,我们可以看一下"正常世界"可以向"安全世界"发布的命令格式。
SMC 和 SCM
令人困惑的是,高通公司选择将"正常世界"通过 SMC 操作码与"安全世界"互动的渠道命名为 SCM(安全通道管理器)。
总之,正如我在之前的博文中提到的,"qseecom"驱动程序用于使用 SCM 与"安全世界"进行通信。
高通公司在相关源文件中提供的文档相当广泛,足以让我们很好地掌握 SCM 命令的格式。
简而言之,SCM 命令可分为两类之一:
常规 SCM 调用
当有信息需要从"正常世界"传递到"安全世界"时,就会使用这些调用,这些信息需要为 SCM 调用服务。内核填充了以下结构:

而 TrustZone 内核在为 SCM 调用提供服务后,将响应写回"scm_response"结构中:

为了分配和填充这些结构,内核可以调用包装函数 “scm_call”,它接收指向内核空间缓冲区的指针,这些缓冲区包含要发送的数据,数据应该被返回的位置,以及最重要的,服务标识符和命令标识符。
每个 SCM 调用都有一个"类别",这意味着哪个 TrustZone 内核子系统负责处理该调用。这是由服务标识符表示的。命令标识符是一个代码,它指定了在一个给定的服务中,哪个命令被请求。
在"scm_call"函数分配和填充"scm_command"和"scm_response"缓冲区之后,它调用一个内部的"__scm_call"函数,它刷新所有的缓冲区(内部和外部缓冲区),并调用"smc"函数。
这最后一个函数实际上是执行 SMC 操作码,将控制权转移到 TrustZone 内核,像这样:

注意,R0 被设置为 1,R1 被设置为指向本地内核堆栈地址,它被用作该调用的"上下文 ID",R2 被设置为指向分配的"scm_command"结构的物理地址。
这个设置在 R0 中的"魔法"值表明这是一个常规的 SCM 调用,使用"scm_command"结构。然而,对于某些需要较少数据的命令,无缘无故地分配所有这些数据结构是相当浪费的。为了解决这个问题,引入了另一种形式的 SCM 调用。
原子 SCM 调用
对于参数数量相当少的调用(最多四个参数),存在另一种请求 SCM 调用的方式。
有四个包装函数,“scm_call_atomic_[1-4]”,它们与请求的参数数量相对应。这些函数可以被调用,以便直接发出一个 SMC,用给定的服务和命令 ID,以及给定的参数进行 SCM 调用。
下面是"scm_call_atomic1"函数的代码:

其中 SCM_ATOMIC 被定义为:

注意,服务 ID 和命令 ID 都被编码到 R0 中,同时还有调用中的参数数(在本例中是 1)。这取代了以前用于常规 SCM 调用的"神奇"的 1 值。
R0 中的这个不同的值向 TrustZone 内核表明,下面的 SCM 调用是一个原子调用,这意味着参数将使用 R2-R5 传递(而不是使用 R2 指向的结构)。
分析 SCM 调用
现在我们已经了解了 SCM 调用的工作原理,并且找到了 TrustZone 内核中用于处理这些 SCM 调用的处理函数,我们可以开始反汇编 SCM 调用,试图在其中找到一个漏洞。
我将跳过对 SCM 处理函数的大部分分析,因为它的大部分是对用户输入的模板处理,等等。然而,在将堆栈切换到 TrustZone 区域并保存执行调用的原始寄存器后,处理函数继续处理服务 ID 和命令 ID,以确定应该调用哪个内部处理函数。
为了方便服务和命令 ID 与相关处理函数之间的映射,一个静态列表被编译到 TrustZone 镜像的数据段,并被 SCM 处理函数引用。下面是该列表的一个简短片段:

正如你所看到的,该列表有以下结构:
- 指向包含 SCM 函数名称的字符串的指针
- 调用的"类型"
- 指向处理函数的指针
- 参数的数量
- 每个参数的大小(每个参数有一个 DWORD)。
- 服务 ID 和命令 ID,串联成一个 DWORD - 例如,上面的"tz_blow_sw_fuse"函数,其类型为
0x2002,这意味着它属于服务 ID0x20,其命令 ID 为0x02。
现在剩下的就是开始拆解这些函数,并希望能找到一个可利用的错误。
漏洞!
因此,在仔细研究了上述所有的 SMC 调用(全部 69 个)后,我终于找到了以下函数:
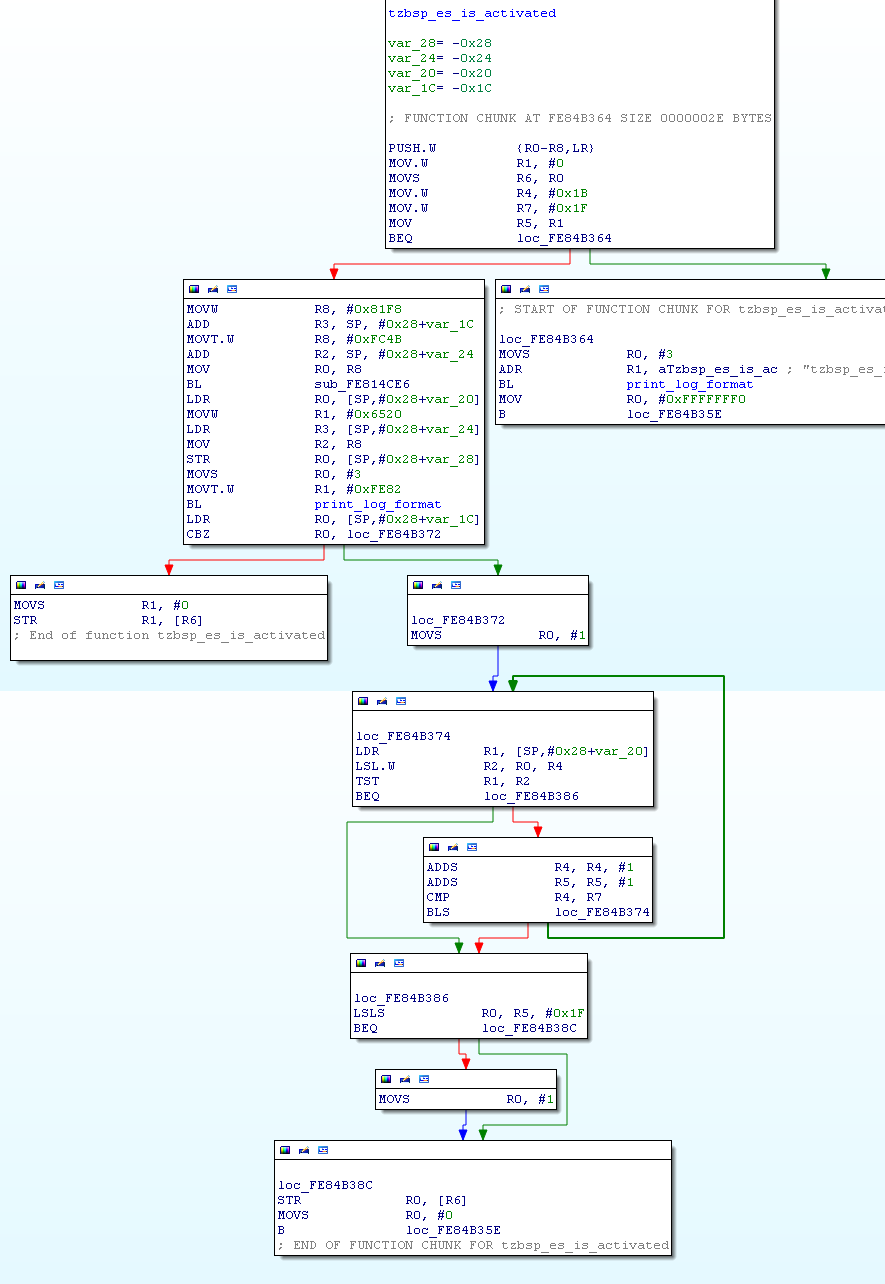
通常情况下,当使用常规的 SCM 调用机制调用 SCM 命令时,R0 将包含"结果地址",它指向由内核分配的"scm_response"缓冲区,但它也被 TrustZone 内核验证,以确保它实际上是一个 "允许"范围内的物理地址,也就是说,一个对应于 Linux 内核内存的物理地址,而不是,例如,TrustZone 二进制中的内存位置。
这个检查是通过一个内部函数进行的,我将在下一篇博文中详细介绍(请继续关注!)。
但是,如果我们使用一个原子的 SCM 调用来执行一个函数,会发生什么?在这种情况下,使用的"结果地址"是原子调用所传递的第一个参数。
现在–你能看到上面这个函数中的错误吗?
相对于其他 SCM 处理函数,这个函数未能验证 R0 中的值,即"结果地址",所以如果我们传入
- R1为非零值(为了传递第一个分支)
- 第四个参数(在上面
var_1C处传入)为非零值 - R0 为任何物理地址,包括 TrustZone 地址空间范围内的一个地址
该函数将到达上述函数中最左边的分支,并在 R0 包含的地址处写入一个DWORD 0。
负责任的披露
我想指出的是,我已经在 11 个月前向高通公司负责任地披露了这个漏洞,而且这个问题已经被他们修复了(速度快得惊人!)。我将在下一篇博文中分享详细的时间表和解释,但我想指出的是,高通公司的人反应非常迅速,与他们合作非常愉快。
下一步是什么?
在下一篇博文中,我将分享一个针对上述漏洞的详细(而且相当复杂!)的利用方法,它可以在 TrustZone 内核内执行全部代码。我还会公布完整的漏洞代码,敬请关注
另外,由于这只是我的第二篇博文,我真的希望得到一些(任何)意见,特别是:
- 我应该多写(或少写)些什么?
- 博客设计问题
- 研究思路 😃